
Editor's Note: The artificial intelligence semantic domain is currently developing at a high speed in China. Capital support has triggered a new wave of entrepreneurship and the bubble has followed. The "black technology" demonstrated by many companies in DEMO and the utmost praise for AI have caused great harm to the development of the industry. How to measure related technologies in the semantic domain is of common concern. Based on years of experience in theory and related technologies, we will publish a series of detailed interpretation and evaluation criteria articles for the four directions technologies in the semantic domain.
This article "Task-Driven Multiple Rounds of Conversational Evaluation Standards [One of the Human-Medical Dialogue Evaluation Series]" was provided by Zhuoran Wang, the CEO of Triangle. Dr. Zhuran Zhu has participated in the evaluation of DSTC 2013. During this period, he proposed a domain-independent conversation state tracking algorithm that was nominated for the Best Paper of the SIGDial 2013 International Conference. The system was used as the official baseline for DSTC 2014 (ie DSTC 2&3). system.
Human-machine dialogue is a sub-direction of the field of artificial intelligence. Popularly speaking, people can interact with computers through the human language (natural language). As one of the ultimate challenges of artificial intelligence, a complete human-computer dialogue system involves a wide range of technologies, such as speech technology in computer science, natural language processing, machine learning, planning and reasoning, knowledge engineering, and even linguistic recognition. Many of theories in knowledge science have been applied in man-machine conversations. In general, human-computer dialogue can be divided into the following four sub-questions: open-domain chat, task-driven rounds of dialogue, questions and answers, and recommendations.
Human-machine dialogue overview
We use the following examples to illustrate the different manifestations of these four types of problems.
 Figure 1: Example of human-machine dialogue
Figure 1: Example of human-machine dialogue
Open domain chat: As the name implies, it is a chat that does not limit the topic, that is, the system responds when the user's query does not use explicit information or services to obtain requirements (such as social dialogue).
 Lines 1-2 in Figure 1, typical examples of open domain chat
Lines 1-2 in Figure 1, typical examples of open domain chat
Open-domain chat plays an important role in the existing human-machine dialogue system. It mainly uses close distances, establishes trust relationships, accompanies emotions, smooths the dialogue process (such as when task-based conversations fail to meet user needs), and enhances the role of user stickiness.
Task-driven rounds of dialogue: The user comes with a clear purpose and wants information or services that meet certain restrictions, such as ordering meals, booking tickets, finding music, movies, or some kind of merchandise, and so on. Because the needs of users may be more complex, it may be necessary to make statements in multiple rounds. Users may also constantly modify or improve their needs during the dialogue. In addition, when the user's stated requirements are not specific or clear, the machine can also help the user find satisfactory results by asking, clarifying or confirming.
Therefore, the task-driven multi-round dialogue is not a simple process of natural language understanding and information retrieval, but a decision-making process that requires the machine to continuously determine the next best action to be taken based on the current state during the dialogue (eg: Provide results, ask specific restrictions, clarify or confirm requirements, etc.) to most effectively assist users in the task of obtaining information or services. The Spoken Dialogue Systems (SDS) mentioned in the academic literature generally refer to task-driven rounds of dialogue.

Lines 3-6 in Figure 1 are examples of mission-driven rounds of dialogue in a musical field
Q&A: Focus more on the question and answer, that is, give a precise answer based on the user's question. The question and answer is closer to the process of information retrieval. Although it may involve simple context processing, it is usually accomplished by referring to resolution and query completion. The fundamental difference between a question-answering system and task-driven rounds of dialogue is whether the system needs to maintain a representation of the user's target state and whether a decision-making process is required to complete the task.

Lines 8-9 in Figure 1, an example of a question and answer
Recommendations: The open-domain chat, task-driven rounds of dialogue and question-answering systems in the first place are all passive responses to the user's query, while the recommendation system is based on the current user query and historical user portraits to actively recommend the user may be interested in Information or service, such as the example of line 7 in Figure 1.

Because the above-mentioned four types of systems have different problems to be solved and different technologies are implemented, it is not realistic to use a set of systems to realize all the functions. In order to integrate these functions into one application, we also need a central control decision module. The reason for this decision is that the module is not only responsible for the classification of requirements and problems, but also includes clarifications, confirmations, and cross-domain guidance among tasks. Therefore, the best technical implementation should also be achieved through a decision-making process. 1].
The human-machine dialogue system for commercial applications may be a complex system that simultaneously synthesizes the above four types of problems according to different application scenarios, and may also simply solve one type of problem. For example, the well-known Apple Siri, Microsoft Cortana, and Baidu Duchai voice helper products integrate the above four types of problem comprehensive systems (but the chat functions of Siri and Cortana cannot be considered as open domains, but are artificially edited for high-frequency queries. Corresponding words, when the user's chat query is not within the pre-configured range, the system responds with a fixed answer such as “I don’t understand.†The secret open-domain chat uses more advanced data based on massive data. Search chat technology. The discussion of related technologies is beyond the scope of this article, we will explain in the follow-up article.) The current smart customer service system is mainly to solve the questions and answers and recommended problems; Microsoft launched the "Little Ice", Including the subsequent launch of the same type of product Japanese version of Rinna, English version of Zo and Ruuh, the main is the open domain chat; and many booking, booking hotel class dialogue system is a typical application of mission-driven multi-round dialogue.
Questions and answers are relatively classic questions, and their respective technologies and evaluation systems are relatively familiar to the industry. So this article begins with task-driven rounds of dialogue.
Task-driven rounds of dialogue
First of all, we come to popularize the task-driven multi-round dialogue system. Figure 2 is a classic block diagram of a task-driven multi-round dialogue system in academic literature.
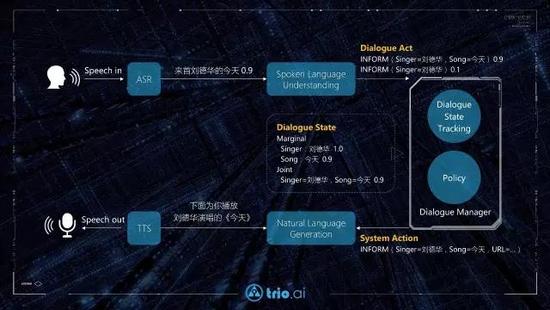
Figure 2: A classic block diagram of a task-driven multi-round dialogue system
Natural language understanding: The natural language query is identified as a structured semantic representation. In a dialogue system, this structured semantic representation is often referred to as the dialog event and consists of communicative functions and slot-value pairs. The communicative function represents the type of the query (eg, statement requirements, query attributes, negation, choice questions, etc.) And each slot-value pair expresses a constraint, which can also be understood as a unit of the user's goal.
For example, the “dialogue act†corresponding to “I want Sichuan cuisine near Xi Er Qi†can be expressed as inform (foodtype=Szechuan, location=Xi Er Qi). Here, "inform" is a communicative function, indicating the need for a statement, and "foodtype=Szechuan cuisine" and "location=Xiliangqi" are the slot-value pairs. The commonly used communicative function definition can refer to the set used in the University of Cambridge's dialogue system [2], while the linguist Harry Bunt et al. concluded that the ISO-24617-2 standard contains 56 definitions of the communicative function, and it The extended set DIT++ contains 88 definitions. However, due to the complexity of the ISO-24617-2 and DIT++ systems, only a small subset of the usual task-driven class dialogue systems will suffice to meet the requirements, but interested readers can refer to the DIT++ website (1).
Since the dialogue system pays more attention to spoken language processing and usually processes spoken speech after speech recognition, we often say Spoken Language Understanding (SLU) in this field to highlight differences from natural language understanding in a broad sense and imply that Non-rigorous grammar and speech recognition errors are robust problems.
Dialogue Status Tracking: Frankly speaking this translation is a bit weird. In English, this concept is called Dialogue State Tracking (DST) and it seems to be much more pleasing to the eye. In a nutshell, conversation status tracking is a process of determining what the user's current goal is based on multiple rounds of dialogue. In order to better understand this process, let us first look at what is the status of the dialogue. In a conversational state, the most important information is the user's purpose, the user goal. The representation of the user's purpose is a combination of a set of slot-value pairs.

Lines 3-6 in Figure 1
The probability distribution is called the belief state or belief. Therefore, conversation state tracking is sometimes also referred to as belief state tracking.
In order to facilitate the following explanation, here are two concepts. The purpose of the user's purpose in a confidence state can be divided into two parts: First, each slot can have multiple possible values, and each value corresponds to a confidence probability. This forms the marginal belief on each slot; then the probability distribution of the combination of these possible slot-value pairs forms the joint confidence state (joint be still with lines 3-6 in Figure 1). For example, when the dialogue goes to line 3, the purpose of the user is “occasion=runningâ€, and when line 5 is reached, this goal becomes “occasion=running, language=Englishâ€. Other additional information required to complete the dialogue task is recorded, such as the user's current requested slots, the user's communication method, and the user's or system's historical dialog history.
In addition, everyone should have noticed that whether ASR or SLU is a typical classification problem, since there is an error in classification, this introduces a problem of decision-making uncertainty in a task-driven dialogue system. ). Although the final decision is made by the dialogue strategy described below, the dialogue state needs to provide the basis for subsequent decisions, that is, how to describe this problem of uncertainty. To solve this problem, first of all, we want ASR or SLU (or both) to output a confidence score while outputting the classification result, and it is also preferable to give multiple candidate results (n-best list) to better guarantee the recall. . Then the conversation state tracking module not only needs to maintain a dialogue state but also evaluates all possible conversational states based on the above confidence and n-best list, ie, the probability distribution of the user's complete purpose. Usually the decision-making process of the dialogue system needs to refer to these two parts of information in order to find the optimal dialogue strategy.
Conversation strategy: That is, policy is the process of making decisions based on the confidence state described above. The output of the conversation strategy is a system action. Similar to the user's dialog event, the system action is also a semantic representation consisting of communicative functions and slot-value pairs, indicating the type of the action to be performed by the system and the operating parameters. "The goal of each decision is not the right and wrong of the current action, but the choice of the current action will maximize the expected long-term reward."
Natural language generation: The task of the natural language generation (NLG) is to translate the semantic representation of conversational strategy output into natural language sentences and feed it back to the user.
With the above basic knowledge, we can get to the point: How to evaluate a task-driven multi-round dialogue system? In the following, we will introduce the two parts of the dialogue tracking and dialogue strategy in detail.
Wait, why not talk about SLU and NLG? First of all, the essence of SLU is a structured classification problem. Although the models used may vary widely and vary in complexity, the evaluation criteria are relatively clear. They are nothing more than accuracy, recall, F-score, etc. Therefore, this is not the case here. Discussed in detail. As for NLG, as far as I know, the NLG part of the current business application dialogue system is mainly solved by templates, so there is nothing to evaluate. Not that the NLG problem itself is simple, but the ability of the existing dialogue system is far from reaching the point where it is necessary to optimize the NLG to enhance the user experience. The previous series of problems have not yet been resolved to the extreme. The template language is inflexible. Not the bottleneck. Of course, the academic community has accumulated research on the NLG problem for many years. Interested readers can refer to the previous employers of Heriot-Watt University Interaction Laboratory Oliver Lemon, Helen Hastie and Verena Rieser, Hall University Nina Dethlefs, and Cambridge University dialogue group Tsung-Hsien Wen's work.
Dialog State Tracking Evaluation Method: Speaking from Dialog State Tracking Challenge
Although conversation state tracking is essentially a classification problem, DST maintains a probability distribution as a key step in assisting dialogue strategy decision-making. Then two problems are introduced here: (1) How to measure the pros and cons of a probability distribution (2) Which round of assessment is appropriate. Below we analyze these issues with the results of the 2013 Dialog State Tracking Challenge (DSTC)(2) evaluation.
DSTC 2013 is the first public evaluation of the state of the conversation state tracking in the world. It is jointly organized by Microsoft Research Institute, Honda Research Institute and Carnegie Melody University. The evaluation data is from the real user log of the Pipsburg bus route automatic query system over the past 3 years. The evaluation provides 5 sets of training sets and 4 sets of test sets for testing the following four cases respectively:
(1) There is training data from the same ASR, SLU, and conversation strategy as the test set;
(2) There is training data from the same ASR and SLU as the test set, but the dialogue strategy is different;
(3) Only a small amount of training data from the same ASR, SLU, and conversation strategy as the test set;
(4) ASRs, SLUs, and conversation strategies that generate test data are all different from systems that produce training samples.
Except for the ASR tagging of the two training sets, the other training sets provide manually labeled ASR, SLU, and DST results. A total of 11 teams participated in this review and 27 systems were submitted. Since it was the first evaluation, the organizer put forward 11 kinds of evaluation indicators and 3 kinds of evaluation schedules as reference, as detailed below:
Hypothesis accuracy: The accuracy of the top hypothesis in the confidence state. This standard measures the quality of the first hypothesis.
Mean reciprocal rank: The average of 1/R, where R is the order of the first correct assumption in the confidence state. This criterion is used to measure the quality of ranking in the confidence state.
L2-norm: The L2 distance between the probability vector of the confidence state and the 0/1 vector of the real state. This criterion is used to measure the quality of the probability in the confidence state.
Average probability: The average of the probability scores for the real state in the confidence state. This criterion is used to measure the quality of the probability estimate of the real state of the confidence state.
ROC performance: The following set of indicators characterize the distinguishability of the first hypothesis in the confidence state.
Equal error rate: The intersection of false accepts (FAs) and false rejects (FRs) (FA=FR).
Correct accept 5/10/20: Correct accepts (CAs) when there are at most 5%/10%/20% of FAs.
The above ROC curve-related indicators adopt two ROC calculation methods. The first way to calculate the ratio of CA is that the denominator is the total number of all states. This approach takes into account the accuracy and distinguishability. The second way to calculate the ratio of CA is that the denominator is the number of all correctly classified states. This calculation method simply considers the factors that can be discriminated from the accuracy rate.

Figure 3: The system submitted by DSTC 2013 is based on the above 11 assessment indicators. Different degrees of sorting results, the smaller the radius of the circle, the more similar the results
The above evaluation criteria measure the quality of the confidence status from different perspectives, but from the analysis of the system results submitted by DSTC 2013, it can be seen that there are strong correlations among some standards, as shown in Figure 3. Therefore, in the subsequent DSTC 2014 evaluation, a subset of the above 11 indicators was selected as the main evaluation indicator.
DSTC 2013 also put forward three kinds of evaluation opportunities, namely:
Schedule 1: Every conversation is evaluated;
Schedule 2: For a slot-value pair, it is only evaluated when the concept is mentioned;
Schedule 3: Evaluate at the end of each conversation.
It can be seen that in the above three assessment opportunities, schedule 2 can better reflect the value in real applications. Schedule 1 is paranoid, because when a concept is mentioned, if the user or the system does not modify the operation, the estimation of the confidence state will not change in most cases. This result will maintain multiple sessions. Therefore, regardless of the quality of this estimate, it will be calculated many times, and it will have an impact on the average value of the evaluation indicators. The problem with Schedule 3 is that it ignores the influence of confidence state quality in the dialogue process. That is, if a concept is repeatedly mentioned or clarified during the dialogue, the change in the confidence probability corresponding to this concept during the dialogue is ignored. . In fact, Schedule 2 also has certain limitations. If there is conflict or mutual influence among concepts, that is, when a user or system refers to a concept, it may potentially affect the confidence probability of other concepts that are not mentioned in the current round. Schedule 2 It is impossible to measure the state changes caused by this influence.
The following year, Cambridge University organized two DSTC evaluations (DSTC 2 & 3 (3)), which proposed two new challenges. In the DSTC2, the dialogue scene was selected as a problem finding a restaurant in Cambridge. Unlike DSTC 2013, this evaluation assumes that the user's goals can be changed during the conversation; then in DSTC 3, the conversation scene extends from finding a restaurant to finding a restaurant or hotel. However, DSTC 3 does not provide additional training data except for a small amount of seed data for debugging. The team needs to use only the training data of DSTC 2 to train the model and migrate to the DSTC 3 test set. The main evaluation indicators of these two evaluations are the schedule 2 based accuracy, L2 norm, and ROC CA 5.
In the following two years, the I2R A*STAR Institute in Singapore organized evaluations of DSTC 4 (4) and DSTC 5 (5). The main goal of the evaluation is to model the state of dialogue in the dialogue between people and people in a tourism setting. Among them, DSTC 5 proposes the challenge of modeling cross-language dialogue through machine translation based on DSTC 4. Since the data from these two evaluations comes from manual labeling and does not include ASR and SLU, the evaluation indicators chosen are based on the accuracy of schedule1 and schedule 2, plus the accuracy, recall rate, and F- of the slot-value pairs output from the participating systems. Score.
There are certain limitations to the current evaluation criteria for conversation state tracking. The main problem is that the above evaluation mechanism is based entirely on structured semantics and dialog state representations. In the real business application dialogue system, a combination of structured representation and non-structural representation is often used to meet the needs of the user. For example, in the dialogue system of the fourth-generation millet television, the triangle beast technology provides a fuzzy semantic understanding technology, which can more accurately satisfy the user's needs when the user's purpose of searching for video cannot be completely structured. However, this unstructured representation is not suitable for evaluation using the above evaluation criteria, but should be evaluated by evaluating the overall dialogue effect.
Evaluation of dialogue strategies
First of all, we once again explained that because the dialogue strategy is a decision-making process, it is impossible to evaluate the merits of a single round of decision-making. Therefore, the evaluation of the dialogue strategy is usually achieved by evaluating the effectiveness of the overall dialogue system.
The core purpose of a task-driven multi-round dialogue system is to help users complete the task of obtaining information or services most effectively. The two most direct indicators for evaluating the quality of a mission-driven dialogue system are the task completion rate and the average number of dialogue rounds. Among them, the higher the task completion rate, the better, and based on the completion rate of the same dialogue, the less the average number of dialogue rounds, the better. Ideally, counting the above indicators requires real people to participate in the dialogue. (Although the early dialog system studies also had precedents for automatic evaluation via dialogue simulators [4], the quality of the dialog simulator itself introduces another dimension.) To obtain the above statistical results, we can either annotate offline The log [5] of the user interacting with the dialogue system can also generate the user's purpose in advance (randomly), and let the live experimenter conduct the dialogue according to the specified purpose [6]. The latter can be done through the common platform of Amazon Mechanical Turk [6]. In addition, if the test is carried out, there are two issues that should be noted: (1) Usually we need to automatically calculate the objective completion rate of the task (by matching the pre-specified user's purpose and the results of the machine's output), and we also need to test the user. Provide subjective perception of task completion. Because according to past research experience, the absolute value of these two results will be different [6]; (2) The main reason for the difference between the subjective and objective task completion rate is that the test user fails to state the requirements for various reasons. Accurate and complete expression of predefined objectives. Therefore, we also need a detection mechanism to test the match between the user's stated requirements and the output of the system [6].
What is worth mentioning here is that, as far as I know, the only public evaluation of the end-to-end dialogue system is the Spoken Dialog Challenge 2010, and its main evaluation indicators are the task completion rate and the average number of rounds of dialogue.
to sum up
A task-driven multi-round dialogue system is evaluated, which mainly involves the evaluation of natural language understanding, conversation state tracking, and dialogue strategy. Natural language understanding is a typical classification problem. It can be evaluated by indicators such as accuracy, recall rate, and F-score. The tracking of conversation status, as an intermediate link in the supporting dialogue strategy, has been summarized by the industry as a series of evaluation criteria. For details, please refer to previous public DSTC evaluations. The quality of the dialogue strategy usually needs to be reflected through the overall effect of the dialogue system. Its main evaluation indicators are the task completion rate and the average number of rounds of dialogue.
references
[1] 烩Wang, H Chen, G Wang, H Tian, ​​H Wu & H Wang (2014) Policy Learning for Domain Selection in an Extensible Multi-domain Spoken Dialogue System. In Proceedings of Conference on Empirical Methods on Natural Language Processing ( EMNLP 2014)
[2] Thomson & S Young (2010) Bayesian update of dialogue state: A POMDP framework for spoken dialogue systems. Computer Speech & Language 24 (4), 562-588.
[3] 燡Williams, A Raux, D Ramachandran & A Black (2013) The dialog state tracking challenge. In Proceedings of the SIGDIAL 2013 Conference.
[4] Scheffler & S Young (2001) Corpus-based dialogue simulation for automatic strategy learning and evaluation. In Proceedings of NAACL Workshop on Adaptation in Dialogue Systems.
[5] Black, S Burger, A Conkie, H Hastie, S Keizer, O Lemon, N Merigaud, G Parent, G Schubiner, B Thomson, J Williams, K Yu, S Young, & M Eskenazi (2011) Spoken Dialog Challenge 2010 : Comparison of Live and Control Test Results. In Proceedings of the SIGDIAL 2011 Conference .
[6] ç„–Jurc?cek, S Keizer, M Ga?ic, F Mairesse, B Thomson, K Yu & S Young (2011) Real user evaluation of spoken dialogue systems using Amazon Mechanical Turk. In Proceedings of INTERSPEECH.
 燑br>
燑br>
maintenance package,service kit,Engine repair kit
Chongqing LDJM Engine Parts Center , https://www.ckcummins.com